


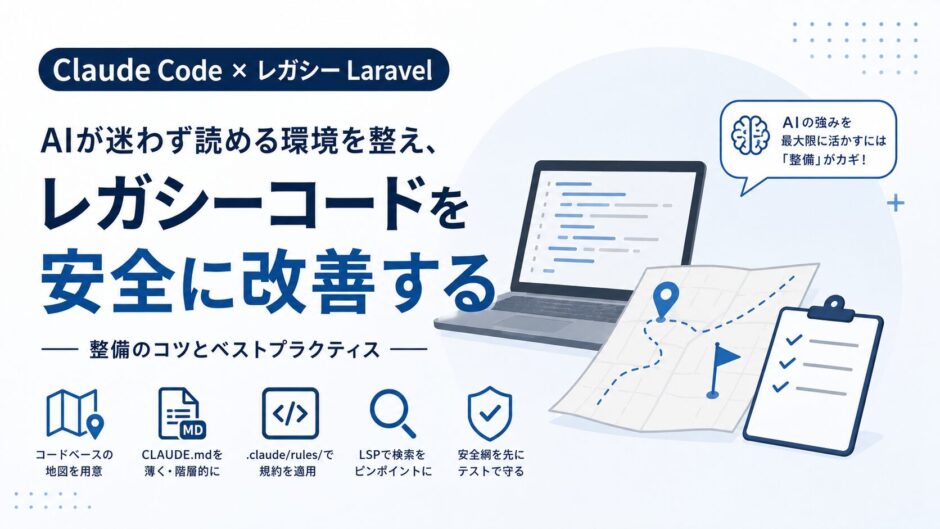
10年もののLaravelに、Claude Codeをどう『効かせる』か ── レガシー読解のための環境整備
こんにちは、AIイノベーションSecの長谷川です。
システム開発の現場で長くお仕事をしていると、いつかは必ず出会うのが「10年もの」のレガシーシステムです。
誰も全体像を把握しておらず、ドキュメントは実態とズレていて、改修のたびに「ここを触ったら、どこが壊れるんだろう……」と冷や汗をかく。
Laravel に限らず、長く動いているシステムに関わったことのある方なら、一度はこんな場面に心当たりがあるのではないでしょうか。
こうしたレガシーコードに対して、最近話題の Claude Code のような AI コーディングエージェントは、実はとても頼もしい「読解の相棒」になってくれます。
ただ、ここで一つだけ、最初に強調しておきたいことがあります。
「AIを使えば、レガシーも自動的に・安く・パパっと片付く」……そういう魔法のような話ではない、ということです。
むしろ逆で、AIがコードベースをきちんと「読める」状態を、こちら側が地道に整えてあげる必要があります。今回は、その整え方を具体的にお話ししていきます!
今回参考にしたのは、Claude Code を開発している Anthropic が公開している、大規模・レガシーコードベース向けの公式ベストプラクティスです。一次情報をしっかり確認しながら、Laravel の現場に当てはめて解説していきますね。
そもそも、なぜレガシー Laravel はこんなに厄介なのか
Laravel はとても生産性の高いフレームワークですが、「長く保守する」という観点では、昔から固有の難しさを抱えてきました。
特に初期のメジャーバージョン間の移行は、なかなかの難物だったんです。
海外の技術ニュースメディア BigGo の報道によると、Laravel 3 から 4、そして 4 から 5 への移行は、コアの書き直しや命名規則の変更を含むほど大がかりで、アップグレードがあまりに大変なために「移行をがんばるくらいなら、いっそ古いバージョンのまま使い続けよう」と判断した組織もあったそうです(出典:BigGo ニュース)。
同じ記事では、2012年にリリースされた Laravel 3 で作られたプロジェクトが、今もなお本番環境で動き続けている例にも触れられています。こうしたシステムは、ちょっとずつ段階的にアップグレードする……というより、完全に書き直すしかないケースが多い、とも指摘されています。
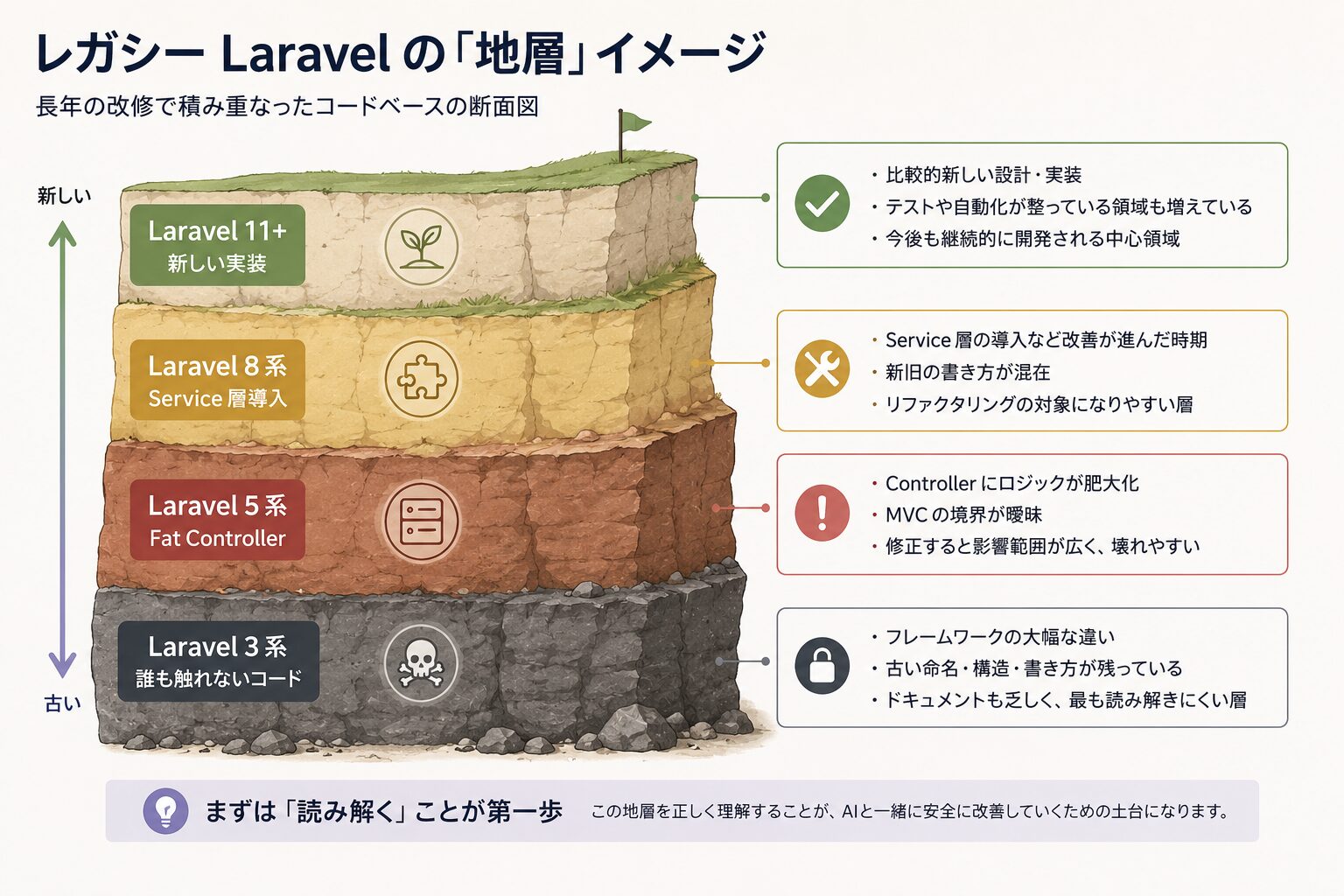
実際の現場には、こんな「地層」のようなコードが積み重なっています。
- フレームワークのバージョンが数世代前で止まったまま
- MVCの境界が崩れて、Controllerにビジネスロジックがぎっしり詰まっている
- ディレクトリ構造が標準から外れていて、どこに何があるか直感的に分からない
- テストが乏しくて、変更したときの影響範囲が読めない
この地層を読み解くこと自体が、まず一つの立派な専門作業なんですね。
では、その読解をAIにどう手伝ってもらうのか。順番に見ていきましょう。
Claude Code はコードを「どうやって読む」のか
具体的な整備手順に入る前に、まず Claude Code がコードをどう探索しているのかを知っておくと、「なんで整備が必要なの?」というところがストンと腑に落ちると思います。
Anthropic の公式記事「How Claude Code works in large codebases」(2026年5月14日公開) によると、Claude Code は私たちエンジニアと同じやり方でコードを辿っていきます。

ファイルシステムを巡って、ファイルを読んで、grep で必要な箇所を探して、コードの参照を追いかけていく——そんな動き方です。しかもこれを開発者のマシン上でローカルに行うので、サーバー側にコードベースのインデックス(索引)を作って維持する必要がありません(出典:Anthropic 公式ブログ)。
「索引を作るタイプ」のAIが、レガシーで弱くなる理由
この「その場で読む」やり方(公式記事では agentic search と呼んでいます)には、レガシー保守において見逃せないメリットがあるんです。
公式記事は、RAG(埋め込みベース検索)という仕組みを使うAIコーディングツールの弱点を指摘しています。
RAGタイプは、コードベース全体をあらかじめ索引化しておいて、質問が来たときに関連しそうな部分を取り出す方式です。便利そうに聞こえますよね。
ところが、活発に開発が進む大規模な現場では、この索引づくりがコミットの速さに追いつかなくなります。すると、2週間前にリネームしたはずの関数や、前回のスプリントで削除したモジュールが、「これは古い情報ですよ」という表示もないまま、しれっと検索結果に返ってくる——こういう”陳腐化”が起きてしまうわけです(出典:同上 Anthropic 公式ブログ)。
その点 Claude Code は、毎回その時点のコード(live なファイルそのもの)を直接読みにいくので、この陳腐化が原理的に起きません。
改修が散発的で、構造も標準から外れがちなレガシー Laravel では、この特性がとてもありがたいんですね。
でも「AIが賢いから何とかなる」わけではないんです
ここが、今回いちばんお伝えしたいポイントです。
公式記事は、この agentic search のトレードオフもはっきり書いています。つまり、Claudeが「どこを見ればいいか」を把握できるだけの十分な手がかりがあって、はじめてこの方式は本領を発揮する、ということなんです。
具体的には、10億行クラスの巨大なコードベースに「曖昧なパターンに当てはまる箇所を全部探して」とお願いすると、作業を始める前にコンテキストウィンドウ(AIが一度に扱える作業メモリのようなもの)の上限に達してしまう、と書かれています。そして公式記事は、コードベースのセットアップにきちんと投資したチームほど、良い結果を得ている、と結論づけています(出典:同上 Anthropic 公式ブログ)。
言い換えると、AIの性能は「賢いモデルを使うこと」で決まるのではなく、「AIがコードベースを読める状態を、人間が整えてあげること」で決まる、というわけです。
公式記事では、この整備の仕組み全体をまとめて harness(ハーネス) と呼んでいて、モデル単体の性能よりも、このharnessの整備度合いのほうがClaude Codeの働きを左右する、と述べています。なかなか興味深い視点ですよね。
ちなみに、Laravelユーザーにとって嬉しい記述もありました。
公式記事は、AIコーディングツールと一緒に語られることが少ない言語——C、C++、C#、Java、そして PHP——を含むコードベースでも、Claude Code は多くのチームの予想以上にしっかり動く(特に最近のモデルでは顕著)と明言しているんです(出典:同上 Anthropic 公式ブログ)。PHP/Laravel のレガシーは、まさにこの恩恵を受けられる領域というわけですね。
実践:レガシー Laravel を「AIがナビゲートできる」状態にする
では、具体的に何を整えればいいのか。
公式記事が挙げている「コードベースをナビゲート可能にする」ためのパターンを、Laravelの現場に当てはめながら、一つずつ見ていきましょう。
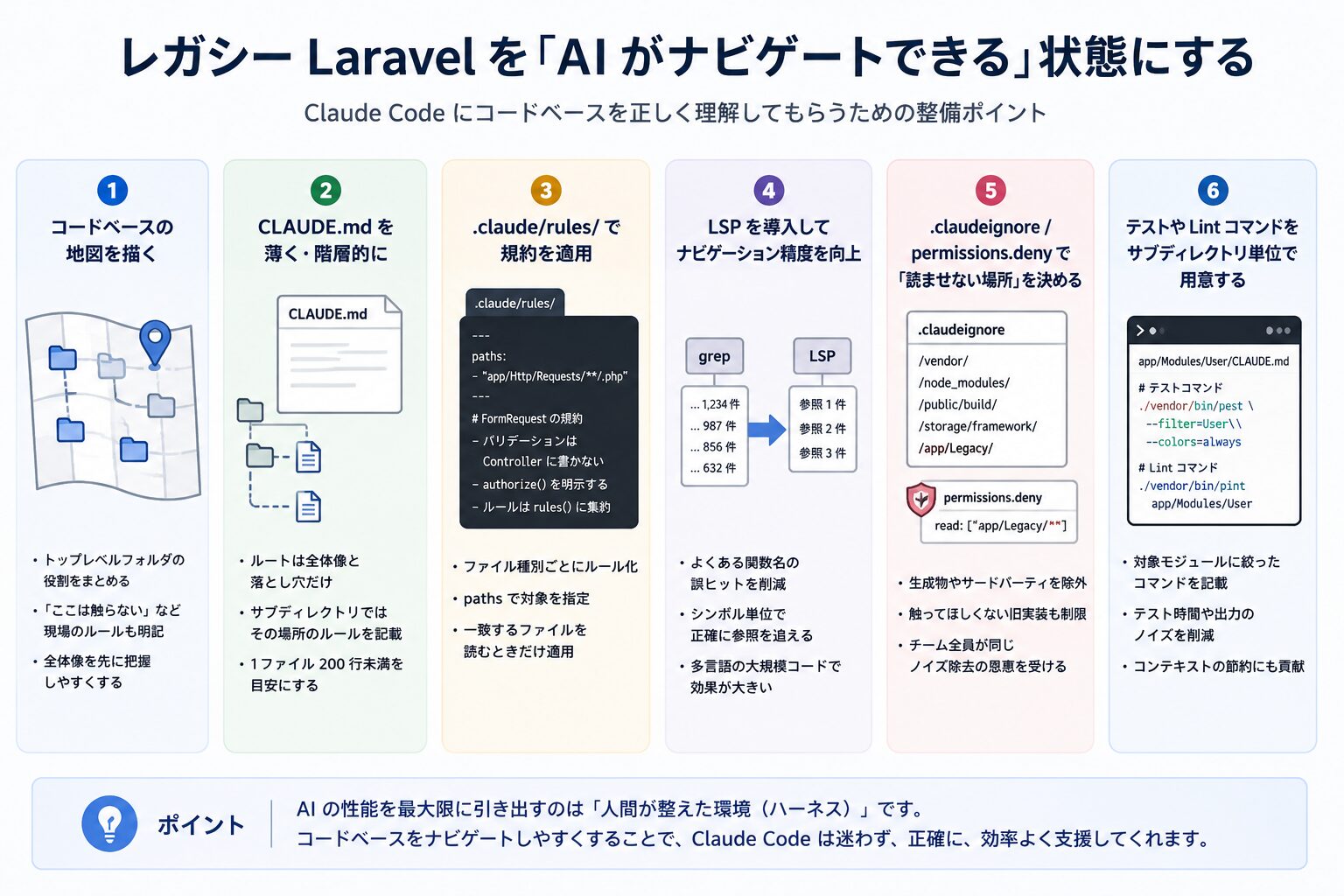
1. まずは「コードベースの地図」を描いてあげる
公式記事では、コードが標準的なディレクトリ構造に収まっていない場合の工夫として、リポジトリのルートに軽いMarkdownファイルを置き、各トップレベルフォルダが何を担当しているかを一行ずつ書いておく「目次」を用意することを勧めています。こうしておくと、Claudeはファイルを実際に開く前に、全体像をサッと把握できるんですね(出典:Anthropic 公式ブログ)。
MVCの境界が崩れがちなレガシー Laravel では、これが特に効きます。たとえば CLAUDE.md に、こんな地図を書いておくイメージです。
# コードベース地図
- app/Http/Controllers/ ... 画面・APIの入口。一部にロジックが肥大化(リファクタ対象)
- app/Services/ ... ビジネスロジック(2020年以降に切り出した分のみ)
- app/Models/ ... Eloquentモデル。レガシー期はモデルに業務処理が混在
- app/Legacy/ ... 旧実装。新規の参照は原則禁止。改修時は要相談
- resources/views/ ... Bladeテンプレート。一部に旧PHPテンプレートが残存「ここは触っちゃダメ」「ここは新しめ」といった現場の事情を地図に書いておけるのが、地味に便利なんです。
2. CLAUDE.md は「薄く・階層的に」が基本
Claude Code は、セッションを開始するときに CLAUDE.md という指示ファイルを自動で読み込みます。
公式記事はこれをharnessの出発点と位置づけていて、「ルートには全体像を、サブディレクトリにはその場所ごとのローカルな規約を」という、薄く階層化する設計を推奨しています。ルートのファイルには道しるべと致命的な落とし穴だけを書いて、あれもこれも詰め込むとかえってノイズになる、とのことです(出典:Anthropic 公式ブログ)。
公式ドキュメント「How Claude remembers your project」では、サイズの目安として 1ファイルあたり200行未満を勧めています。これより長くなると、コンテキストをたくさん消費するうえに、指示の守られ具合も下がってしまうからだそうです(出典:Claude Code 公式ドキュメント)。
読み込まれるタイミングにも、知っておくとちょっと得する挙動があります。
公式ドキュメントによると、作業ディレクトリより上の階層にある CLAUDE.md は起動時にまとめて読み込まれ、サブディレクトリにあるファイルは、Claudeがそのディレクトリのファイルを読んだときにオンデマンドで(必要になってから)読み込まれます(出典:同上 Claude Code 公式ドキュメント)。
つまり階層化は、「上位のルールは常に効かせつつ、下位の細かいルールは必要なときだけ読む」という、コンテキスト節約の仕組みになっているわけですね。
3. ルートではなく「サブディレクトリ」で作業する
公式記事は、リポジトリのルートではなく、サブディレクトリにスコープを絞って作業することを勧めています。
「えっ、ルートから全体を見せたほうがいいんじゃないの?」と直感的には思いますよね。でも、Claudeは自動的にディレクトリツリーを上へ遡って、道中で見つけた CLAUDE.md を全部読み込んでくれるので、ルートのコンテキストが失われる心配はないんです(出典:Anthropic 公式ブログ)。
むしろ、今のタスクに本当に関係する範囲にギュッと絞ってあげたほうが、Claudeは集中して働いてくれます。
4. テストやLintのコマンドは、サブディレクトリ単位で指定する
Claudeが一つのモジュールだけを直したのに、コードベース全体のテストを走らせてしまうと、タイムアウトしたり、関係ない出力でコンテキストを無駄遣いしたりしてしまいます。
そこで公式記事は、サブディレクトリ単位の CLAUDE.md に、その範囲に適用するコマンドを書いておくことを勧めています(出典:Anthropic 公式ブログ)。
Laravelなら、特定のモジュールに対応する PHPUnit / Pest のフィルタ指定などを、ここに書いておくイメージですね。
5. .claude/rules/ で、Laravelの規約を「ファイル種別ごと」に効かせる
公式ドキュメントには、CLAUDE.md と並ぶもう一つの仕組みとして .claude/rules/ ディレクトリが紹介されています。
YAMLフロントマターの paths という項目でパターンを指定しておくと、Claudeがそのパターンに一致するファイルを扱うときだけ、ルールが読み込まれるんです(出典:Claude Code 公式ドキュメント)。
これ、レガシー Laravel のリファクタ方針を、ファイルの種類ごとに分けて書いておくのにぴったりです。
たとえば、「バリデーションはController直書きをやめて、FormRequestに寄せていこう」という方針を、こんなふうに書けます。
---
paths:
- "app/Http/Requests/**/*.php"
---
# FormRequest の規約
- バリデーションは Controller に直接書かず、FormRequest に集約する
- authorize() は要件に応じて明示的に実装する(true 固定で済ませない)
- ルールは rules() にまとめ、メッセージは messages() で日本語化する公式ドキュメントによると、paths を書かなかったルールは毎セッション無条件で読み込まれ、paths 付きのルールは一致するファイルを読んだときだけ適用されます(出典:同上 Claude Code 公式ドキュメント)。
「テスト規約」「認証まわりの注意点」「APIハンドラの書き方」などを、1トピック1ファイルに分けて管理できるので、とても見通しが良くなりますよ。
6. LSPを導入して、grepの限界を超える
レガシーコードあるあるなんですが、似たような名前の関数やメソッドが、あちこちに散らばっていることってありますよね。
公式記事も、大規模コードベースで「よくある関数名」を grep すると数千件もヒットしてしまい、どれが本命なのかを判断するためにClaudeがファイルを次々と開いて、コンテキストを浪費してしまう、と指摘しています。
これを防いでくれるのが LSP(Language Server Protocol)統合です。
LSP を Claude につないであげると、同じシンボルを指している参照だけがピンポイントで返ってくるので、Claudeがファイルを読む前に絞り込みが終わっているんです。
公式記事では、ある大手エンタープライズソフト企業が、C / C++ のナビゲーションを大規模に信頼できるものにするために、Claude Code の全社展開に先立ってLSP統合を全社整備した、という例が紹介されていて、多言語のコードベースにおいては最も投資対効果の高い施策の一つだと位置づけられています(出典:Anthropic 公式ブログ)。
なお公式記事は、LSPを設定するには対象言語の code intelligence プラグインと、対応する language server バイナリのインストールが必要で、使えるプラグインやトラブル対処は公式ドキュメントで扱っている、としています(出典:同上 Anthropic 公式ブログ)。
PHPの場合も、対応する language server を用意してあげれば、シンボル単位でのナビゲーションができるようになります。
7. .claudeignore / permissions.deny で「読ませない場所」を決める
公式記事は、生成ファイルやビルド成果物、サードパーティのコードを除外するために ignore ファイルを使うこと、そして .claude/settings.json に permissions.deny ルールをコミットしておくことを勧めています。こうしておけば、バージョン管理された形でチーム全員が同じ「ノイズ除去」の恩恵を受けられる、というわけです(出典:Anthropic 公式ブログ)。
レガシー Laravel なら、vendor/ やビルド済みのアセット、自動生成されるキャッシュ類に加えて、「触ってほしくない旧実装ディレクトリ」を制限対象に入れておくと安心ですね。
「直す」前に「テストで固める」——AIと安全網の正しい順番
ここまで整備できたら、いよいよAIに改修を任せたくなりますよね。
でもその前に、品質を守るためにどうしても押さえておきたい「順番」があります。
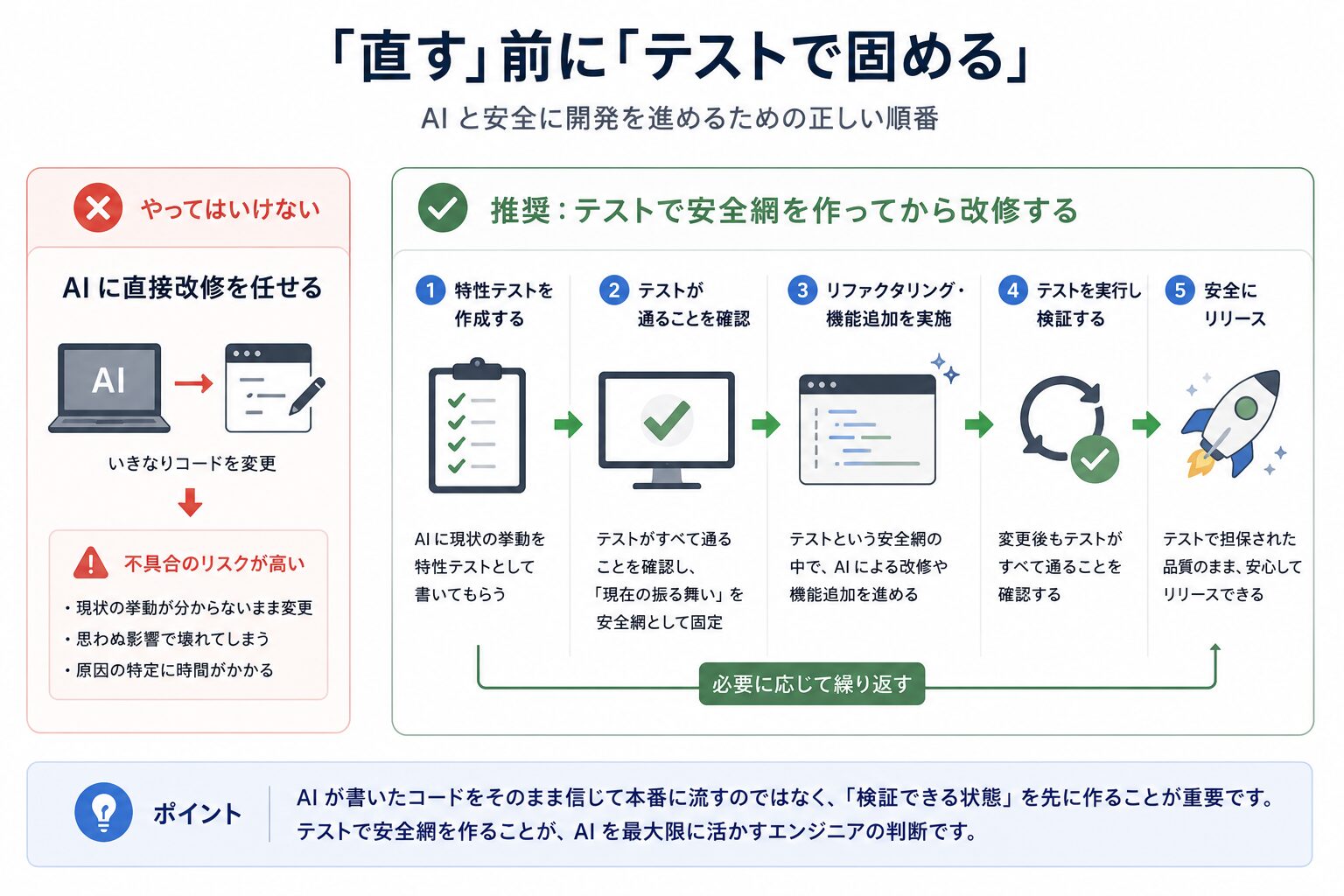
レガシーコード改善のセオリーは、いきなり書き換えるのではなく、まず自動テストを充実させて「変更しても壊れていないことを検証できる状態」を先に作ることです。
実際、リリースから20年を超えるレガシーサービスにLaravelを導入した事例の発表資料でも、改善戦略のいちばん最初に「レガシーコードに自動テストを導入し、変更容易性を向上する」ことが挙げられています(出典:PHP TechCafe 登壇資料(株式会社ラクス))。
この順番は、AIを使う場合でも変わりません。いえ、AIを使うからこそ、むしろ大事になってきます。具体的には、こんな流れです。
- AIにいきなり改修させず、まず今の挙動をそのまま固定する特性テスト(characterization test)を書いてもらう
- そのテストが通ることを確認して、「現在の振る舞い」を安全網として固める
- その安全網の中で、はじめてリファクタリングや機能追加に手をつける
AIが書いたコードをそのまま信じて本番に流すのではなく、検証できる状態を先に作ってあげる。
この判断こそ、AIを扱うエンジニアの腕の見せどころだと思っています。
「AIが書いたから速い」のではなく、「AIを安全に使うための工程をきちんと踏んでいるから信頼できる」——ここはぜひ大事にしたいところですね。
設定は「作りっぱなし」にしないことが大切
最後に、長く保守していく上で見落としがちな、でも大事な話を一つ。
公式記事は、CLAUDE.md・Skills・Hooks といった設定について、3〜6ヶ月ごとに見直しをすることを勧めています。
理由は、モデルそのものがどんどん進化していくからです。今のモデル向けに書いた指示が、将来のモデルではかえって足かせになることがある、というんですね。
たとえば「リファクタは常に1ファイル単位に分割してね」という指示は、昔のモデルを軌道に乗せるのには役立ったかもしれませんが、複数ファイルにまたがる編集を得意とする新しいモデルでは、その良さを邪魔してしまう——そんな具体例が挙げられています(出典:Anthropic 公式ブログ)。
レガシー保守は長期戦です。「一度整えたら終わり」ではなく、モデルの世代交代に合わせて設定もコツコツ育てていく。この継続的なお手入れもまた、私たちの大事な仕事の一つなんですね。
さいごに
今回は、レガシー Laravel に Claude Code をどう「効かせる」か、という話をしてきました。要点をおさらいすると、こんな感じです。
- Claude Code は索引を作らず、その場でlive なコードを読む。だからレガシー特有の「情報の陳腐化」が起きにくい
- ただし、その強みは「Claudeがどこを見ればいいか分かる状態」を人間が整えて、はじめて発揮される。性能を決めるのはモデルそのものより、harnessの整備度合い
- レガシー Laravel では、コードベースの地図づくり・薄く階層化したCLAUDE.md・
.claude/rules/での規約のpaths指定・LSPの導入・読ませない範囲の制限、といった整備が効く - 改修の前に、特性テストで安全網を作る。設定はモデルの進化に合わせて3〜6ヶ月ごとに見直す
レガシーシステムの改修というと、「AIを使っているんだから、安く・速くできるんでしょ?」というイメージを持たれることが、正直なところあります。
でも実態はむしろ逆なんです。AIがレガシーの地層を読み解けるように環境を整えて、安全網としてのテストを敷いて、設定を継続的に保守していく。この一連の手間と判断があってこそ、AIはレガシー保守の現場で本当の力を発揮してくれます。
「古くて、もう誰も触れないシステム」にお困りでしたら、ぜひ一度ご相談ください。一緒に地層を読み解いていきましょう。
それでは、今回はこのへんで!
参考・出典
- Anthropic 公式ブログ「How Claude Code works in large codebases: Best practices and where to start」(2026年5月14日):リンク
- Claude Code 公式ドキュメント「How Claude remembers your project」:リンク
- BigGo ニュース「Laravel が長期保守性と破壊的変更をめぐって批判の声が高まる」(2025年8月):リンク
- PHP TechCafe 登壇資料「リリース後21年目になるレガシーサービスにLaravelを導入した話」(株式会社ラクス、2022年1月):リンク




