


技術
大量の音声データをテキストファイルに変換するツールを作成してみる
お久しぶりです。
ソリューションSec中村です。
業務の都合上、大量の音声データを文字起こしする必要があり、生成AI(Claude)を使用して
変換するまでの流れを今回は共有させてもらえればと思います。
①まずは単純に生成AIに投げてみる
ローカルフォルダに変換したい音声データを保存して、Claudeに場所を指定する。
Claudeに直接テキストデータに変換してくださいと指示を出してみる。。。
結果は・・・

変換失敗!!!
変換モデルのダウンロードが失敗してる。。。
代わりにClaudeが提案してきた内容は、ツールを作成したのでそっちで動かしてみて。。。

② ちょっといろいろ改造してツールを完成させてみた
詳細は若干省きますが、最初に提示してきたツールは使い勝手が悪かったので、
bat起動に変換したり、モデルの決定を自動化したりしたPythonツールが完成した。
下記が作成したPythonツールのコード
### 文字起こし設定条件
- モデル: Whisper **large-v3**(既定)
- 実行環境: `device="cuda"` / `compute_type="float16"`(GPU優先)
- 言語: 日本語(`language="ja"`)固定
※ モデルはlarge-v3だとPC環境で動作しない可能性があるので、動作可能な環境まで設定を落として自動的に決定するようにした。
自PCの環境だとMediumでしか動作できなかった。
# -*- coding: utf-8 -*-
"""
このスクリプトを置いたフォルダ配下のすべての WAV ファイルを文字起こしし、
同階層の「_文字起こし出力」フォルダに <元ファイル名>_transcript.txt として
集約保存します。(時間表示なしの本文のみ・1ファイル/音声)
【特徴】
- サブフォルダも含めて再帰的に処理
- 出力フォルダに同名の <stem>_transcript.txt が既にあればスキップ
(大量ファイルを途中で中断 → 再実行でも続きから処理可能)
- 1 ファイルでエラーが出ても全体は止めず次へ進む
- 音声フォルダ側には何も書き出さない
【モデル / 認識オプション】
- Whisper large-v3
- device="cuda", compute_type="float16"
- vad_filter=True
- condition_on_previous_text=False
【事前準備(初回のみ)】
pip install -U faster-whisper
【実行】
python transcribe_all.py # スクリプトのある場所から再帰検索
python transcribe_all.py <folder> # 指定フォルダから再帰検索
環境変数:
WHISPER_MODEL : 既定 large-v3
AUDIO_EXTS : 既定 .wav
FORCE : "1" にすると既存の出力も上書きで再処理
OUTPUT_DIR : 既定 <ROOT>/_文字起こし出力
"""
import os
import sys
import time
import site
import traceback
from pathlib import Path
# --- Windows: cuBLAS / cuDNN の DLL を実際に探して見つけたディレクトリを登録 ---
import ctypes
import glob
def _add_dll_dirs():
if not (sys.platform == "win32" and hasattr(os, "add_dll_directory")):
return [], []
# 候補ルート(site-packages, user site-packages, CUDA Toolkit, sys.prefix)
roots = []
try: roots.extend(site.getsitepackages())
except Exception: pass
try: roots.append(site.getusersitepackages())
except Exception: pass
roots.append(sys.prefix)
for env in ("CUDA_PATH", "CUDA_HOME", "CUDA_PATH_V12_1", "CUDA_PATH_V12"):
v = os.environ.get(env)
if v:
roots.append(v)
# 必要DLLパターン
patterns = ["cublas64_*.dll", "cublasLt64_*.dll", "cudnn64_*.dll",
"cudnn_*64_*.dll", "cudart64_*.dll", "nvrtc64_*.dll"]
found_dirs = set()
found_files = []
for root in roots:
if not root or not os.path.isdir(root):
continue
# 全 .dll を再帰検索(深さに制限ないがほぼ問題なし)
for pat in patterns:
for hit in glob.iglob(os.path.join(root, "**", pat), recursive=True):
d = os.path.dirname(hit)
found_dirs.add(d)
found_files.append(hit)
added = []
for d in sorted(found_dirs):
try:
os.add_dll_directory(d)
added.append(d)
except Exception as e:
print(f" ! add_dll_directory 失敗: {d} ({e})")
return added, found_files
print("[DLL] CUDA関連DLLを検索中...")
_added, _found = _add_dll_dirs()
if _added:
print(f"[DLL] DLL検索パスに追加 ({len(_added)}件):")
for d in _added:
print(" +", d)
print(f"[DLL] 発見した主要DLL ({len(_found)}件):")
for f in _found[:20]:
print(" ", f)
else:
print("[DLL] cuBLAS / cuDNN のDLLが見つかりませんでした。")
print("[DLL] CPU実行にフォールバックします。")
# 主要DLLを事前ロードしてエラーを早期検出
for _dllname in ("cublas64_12.dll", "cudnn64_9.dll"):
try:
ctypes.WinDLL(_dllname) if sys.platform == "win32" else None
print(f"[DLL] ロード成功: {_dllname}")
except Exception as e:
print(f"[DLL] ロード失敗: {_dllname} ({e})")
try:
from faster_whisper import WhisperModel
except ImportError:
print("faster-whisper が未インストールです。次を実行してください:")
print(" pip install -U faster-whisper")
sys.exit(1)
# --- 設定 ----------------------------------------------------------------
MODEL_SIZE = os.environ.get("WHISPER_MODEL", "large-v3")
EXTS = tuple(
e.strip().lower() if e.strip().startswith(".") else "." + e.strip().lower()
for e in os.environ.get("AUDIO_EXTS", ".wav").split(",")
if e.strip()
)
FORCE = os.environ.get("FORCE", "0") == "1"
INITIAL_PROMPT = (
"ITサポートの電話応対。アクセスソフト、バージョンアップ、PC入替、"
"見積エース、見積書、ライセンスについて。"
)
# --- 対象フォルダ判定 ----------------------------------------------------
if len(sys.argv) > 1:
ROOT = Path(sys.argv[1]).resolve()
else:
ROOT = Path(__file__).resolve().parent
if not ROOT.exists() or not ROOT.is_dir():
print(f"対象フォルダが見つかりません: {ROOT}")
sys.exit(1)
# --- 出力フォルダ --------------------------------------------------------
OUTPUT_DIR_ENV = os.environ.get("OUTPUT_DIR", "").strip()
if OUTPUT_DIR_ENV:
OUTPUT_DIR = Path(OUTPUT_DIR_ENV).resolve()
else:
OUTPUT_DIR = (ROOT / "_文字起こし出力").resolve()
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
print("=" * 70)
print(f"対象フォルダ : {ROOT}")
print(f"出力フォルダ : {OUTPUT_DIR}")
print(f"対象拡張子 : {', '.join(EXTS)}")
print(f"モデル : {MODEL_SIZE} (GPU / CUDA / float16)")
print(f"上書き再処理 : {'はい' if FORCE else 'いいえ (既存ファイルはスキップ)'}")
print("=" * 70)
def output_path_for(audio_path: Path) -> Path:
"""音声ファイルに対応する出力先パス。
同名ファイル衝突時は親フォルダ名をプレフィックスして回避。"""
name = audio_path.stem + "_transcript.txt"
dst = OUTPUT_DIR / name
if not dst.exists():
return dst
# 既存があり、親フォルダ名を付けたいパターン用にメタデータをチェック
tagged = OUTPUT_DIR / (audio_path.parent.name + "__" + name)
return tagged if not tagged.exists() else dst # 既存スキップ判定で使うので元の dst を返す
# --- 対象ファイル列挙 ----------------------------------------------------
all_audio = []
for p in ROOT.rglob("*"):
if not p.is_file():
continue
if p.suffix.lower() not in EXTS:
continue
# 出力フォルダ内は除外
try:
p.resolve().relative_to(OUTPUT_DIR)
continue
except ValueError:
pass
all_audio.append(p)
all_audio.sort()
targets = []
already_done = []
for p in all_audio:
out = OUTPUT_DIR / (p.stem + "_transcript.txt")
tagged = OUTPUT_DIR / (p.parent.name + "__" + p.stem + "_transcript.txt")
if (not FORCE) and (out.exists() or tagged.exists()):
already_done.append(p)
continue
targets.append(p)
print(f"検出した音声ファイル: {len(all_audio)} 件")
print(f" 処理対象 : {len(targets)} 件")
print(f" スキップ(既存): {len(already_done)} 件")
print()
if not targets:
print("処理対象がありません。終了します。")
sys.exit(0)
# --- モデル読み込み(1回だけ・GPU優先 + モデルサイズも自動フォールバック) -
# 優先度の高い順に試す。最初に成功した組み合わせを採用。
# 1) まず希望モデル(既定: large-v3)を GPU で / 精度を順に試す
# 2) ダメなら 1段階小さいモデル(medium → small)を GPU で
# 3) それでもダメなら CPU でそのモデルを int8 で
def _fallback_chain(preferred_model: str):
sizes_desc = ["large-v3", "medium", "small"]
if preferred_model in sizes_desc:
order = sizes_desc[sizes_desc.index(preferred_model):]
else:
order = [preferred_model] + sizes_desc # 想定外モデルでも一応試す
chain = []
for m in order:
chain += [
(m, "cuda", "float16"),
(m, "cuda", "int8_float16"),
(m, "cuda", "int8"),
]
# 最後の保険として CPU(優先モデル)
chain.append((preferred_model, "cpu", "int8"))
return chain
ATTEMPTS = _fallback_chain(MODEL_SIZE)
print(f"優先モデル: {MODEL_SIZE} を読み込み中...")
print("※初回はモデルを自動ダウンロードします (large-v3 は約3GB / medium 約1.5GB)。\n")
t0 = time.time()
model = None
last_err = None
USED_MODEL = USED_DEVICE = USED_COMPUTE = None
for m, dev, ctype in ATTEMPTS:
try:
print(f" 試行: model={m}, device={dev}, compute_type={ctype} ...", flush=True)
model = WhisperModel(m, device=dev, compute_type=ctype)
print(f" → OK: model={m}, device={dev}, compute_type={ctype}")
USED_MODEL, USED_DEVICE, USED_COMPUTE = m, dev, ctype
break
except Exception as e:
last_err = e
print(f" × 失敗: {e}")
if model is None:
print(f"\nモデル読み込みに完全に失敗しました: {last_err}")
sys.exit(1)
print(f"\nモデル読み込み完了 ({time.time() - t0:.1f}秒) "
f"[model={USED_MODEL}, device={USED_DEVICE}, compute_type={USED_COMPUTE}]\n")
# --- 順次処理 -----------------------------------------------------------
ok_count = 0
err_count = 0
err_list = []
for idx, audio in enumerate(targets, 1):
rel = audio.relative_to(ROOT)
print("-" * 70)
print(f"[{idx}/{len(targets)}] {rel}")
# 出力先パス決定(既存衝突したら親フォルダ名プレフィックス)
out = OUTPUT_DIR / (audio.stem + "_transcript.txt")
if out.exists():
out = OUTPUT_DIR / (audio.parent.name + "__" + audio.stem + "_transcript.txt")
n = 2
while out.exists():
out = OUTPUT_DIR / (audio.parent.name + "__" + audio.stem + f"_{n}_transcript.txt")
n += 1
t_start = time.time()
try:
segments, info = model.transcribe(
str(audio),
language="ja",
beam_size=5,
vad_filter=True,
vad_parameters=dict(min_silence_duration_ms=500),
condition_on_previous_text=False,
initial_prompt=INITIAL_PROMPT,
)
print(f" 認識言語: {info.language} ({info.language_probability:.2f}) 音声長: {info.duration:.1f}秒")
lines = []
for seg in segments:
text = seg.text.strip()
if text:
lines.append(text)
out.write_text("\n".join(lines) + "\n", encoding="utf-8")
ok_count += 1
print(f" 保存完了 ({time.time() - t_start:.1f}秒): {out.name}")
except Exception as e:
err_count += 1
err_list.append((str(rel), repr(e)))
print(f" [エラー] {e}")
traceback.print_exc()
# --- サマリ -------------------------------------------------------------
print()
print("=" * 70)
print(f"完了: 成功 {ok_count} 件 / 失敗 {err_count} 件 / スキップ {len(already_done)} 件")
print(f"出力フォルダ: {OUTPUT_DIR}")
if err_list:
print()
print("失敗したファイル:")
for path, msg in err_list:
print(f" - {path} ({msg})")
print("=" * 70)
③ 作成したツールを実行してみる
batファイルを起動してツールを実行してみる
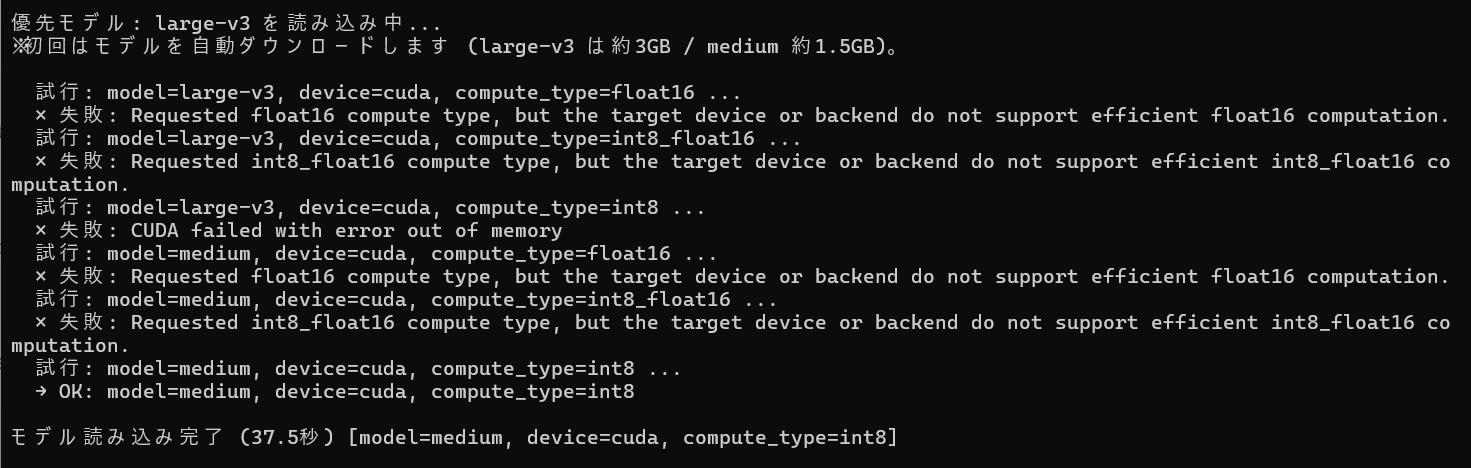
まずは、モデル選択で最終的には、「model=medium, device=cuda, compute_type=int8」で決定。
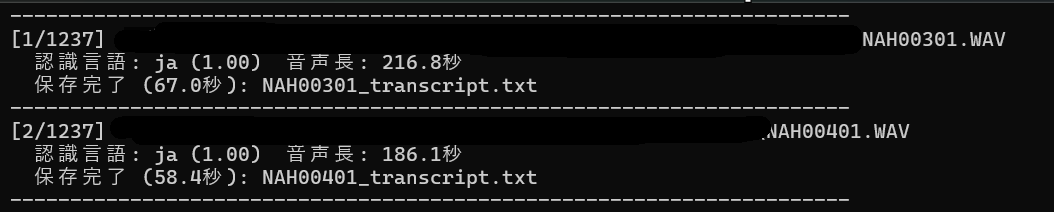
1000件以上あるファイルをテキスト変換開始
ちょっと変換したテキストファイルは機密情報なんで公開は控えますが、
ちょこちょこと誤字とか変換間違いも見られるなか、それなりな状態で文字起こしを進めてくれました。
1000件の文字起こしを大体Total 50h(作業期間としては2週間くらいですが基本的にはバックグラウンドでツールがずっと動いてる状態)で完了出来ました。
④ 次の狙いは
一旦文字起こししたテキストファイルが手に入ったので、
この後はRAGに纏めて、最終的にはQ&Aツールの形に纏められればと思います。
RAG化やQ&Aツールの作成工程に関しては、また後日公開できればと思います。
では、また次回に!!




